Create and Share Data APIs Fast.
Made for Analytics Engineers.
No backend skills required. Empower your data sharing, faster.

How VulcanSQL Works
Build
VulcanSQL offers a development experience similar to  dbt. Just insert variables into your templated SQL. VulcanSQL accepts input from your API and generates SQL statements on the fly.
dbt. Just insert variables into your templated SQL. VulcanSQL accepts input from your API and generates SQL statements on the fly.
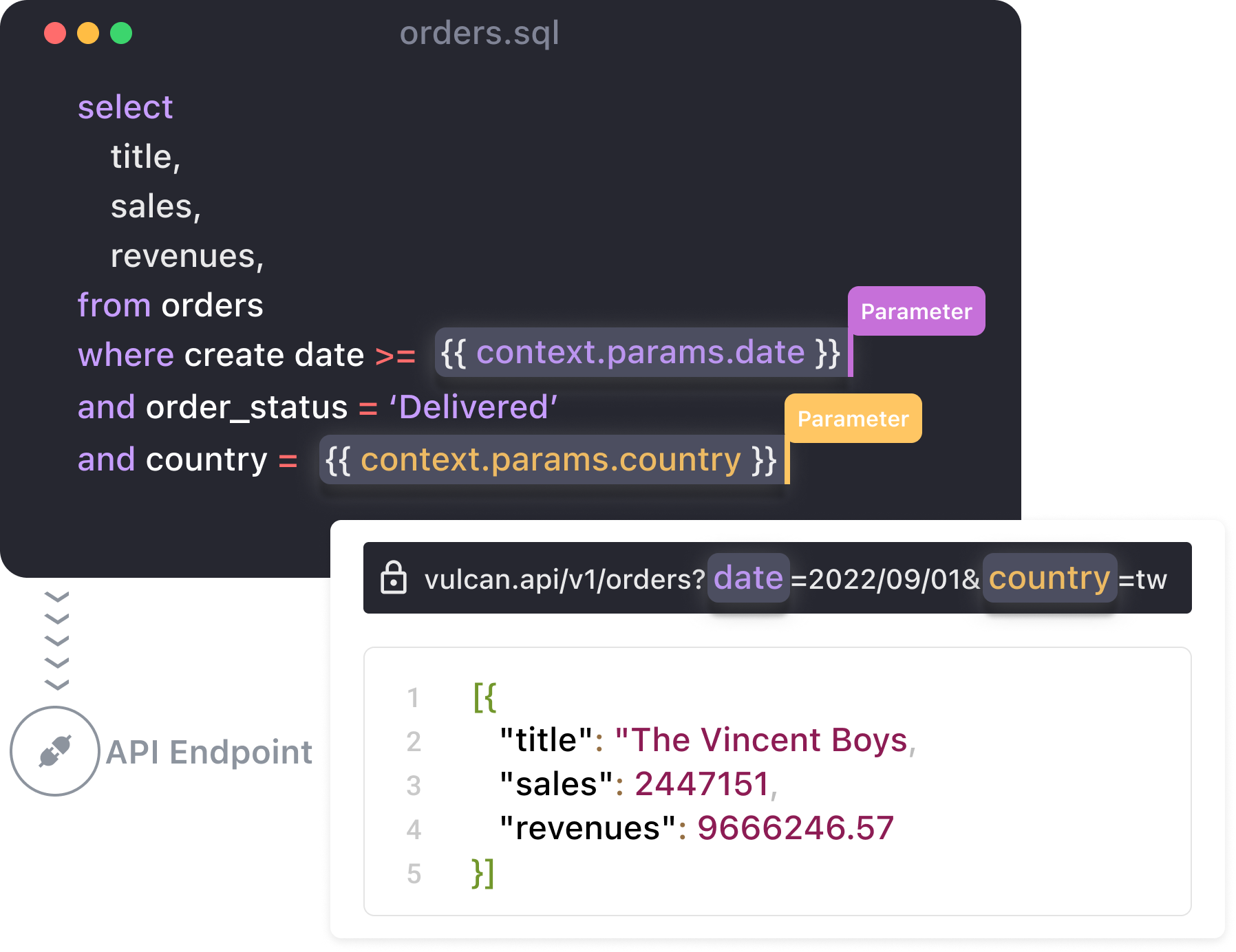
API Best Practices at Your Fingertips
Learn more >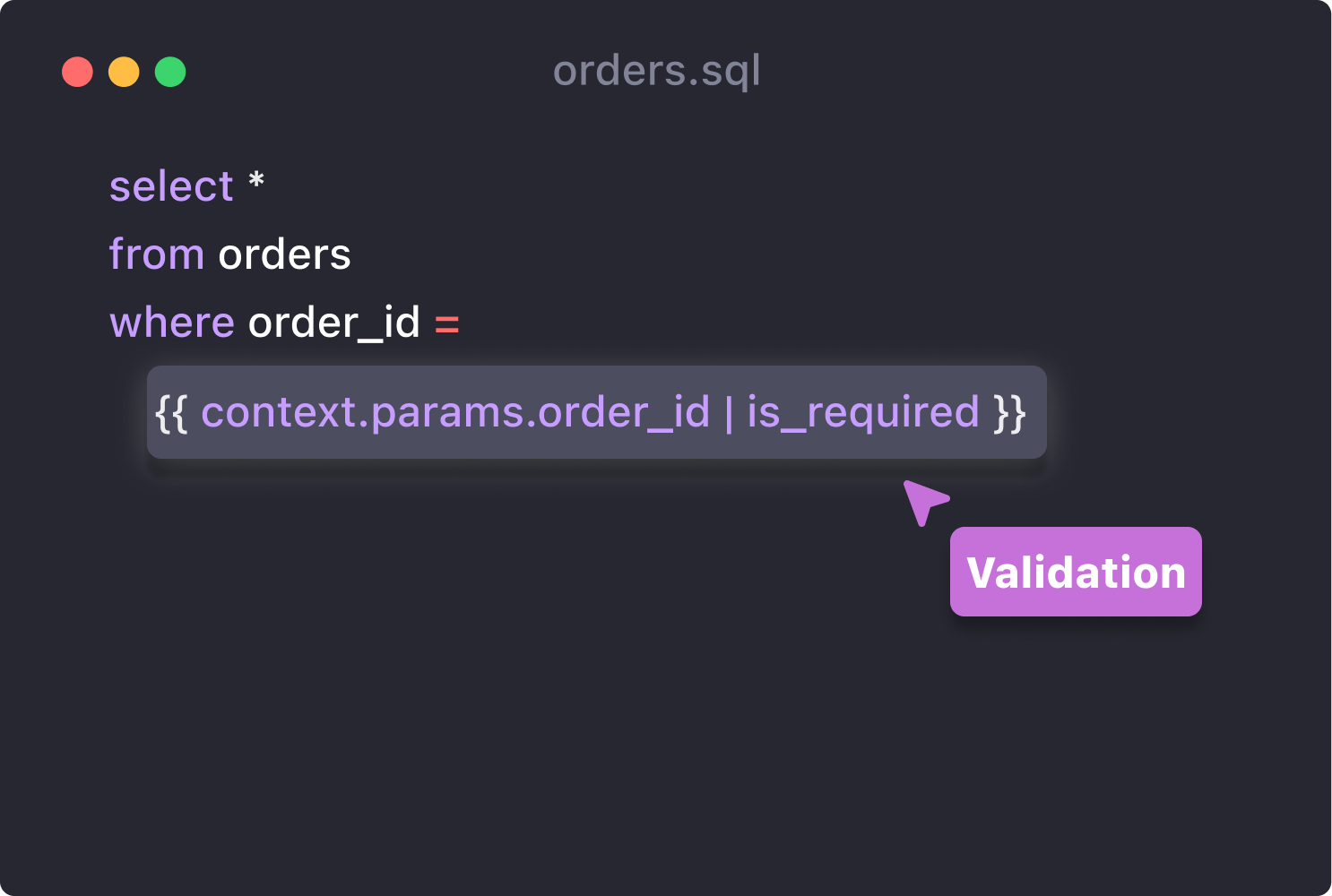
Accelerate
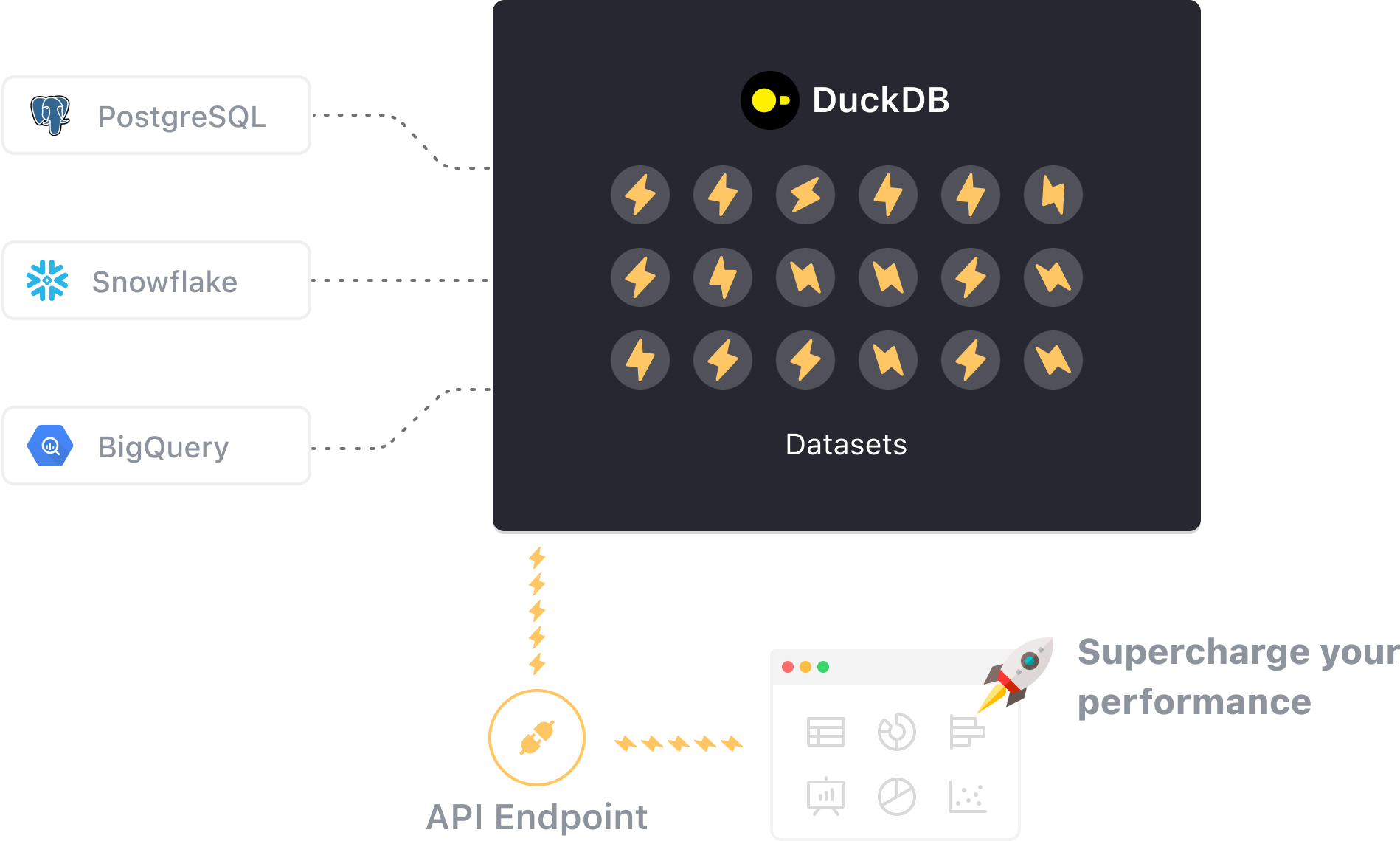
VulcanSQL uses  DuckDB as a caching layer, boosting your query speed and API response time . This means faster, smoother data APIs for you and less strain on your data sources.
DuckDB as a caching layer, boosting your query speed and API response time . This means faster, smoother data APIs for you and less strain on your data sources.
Deploy
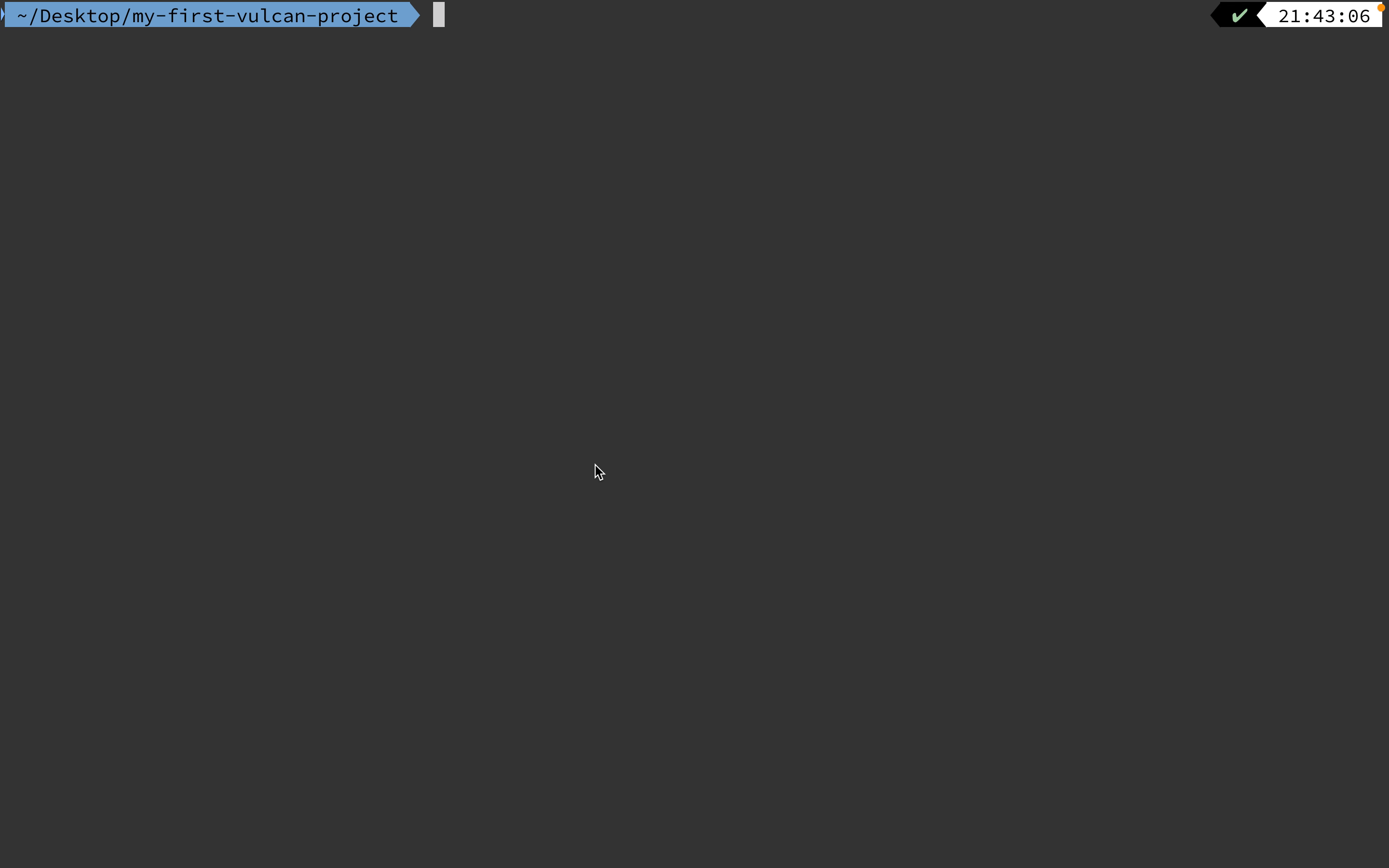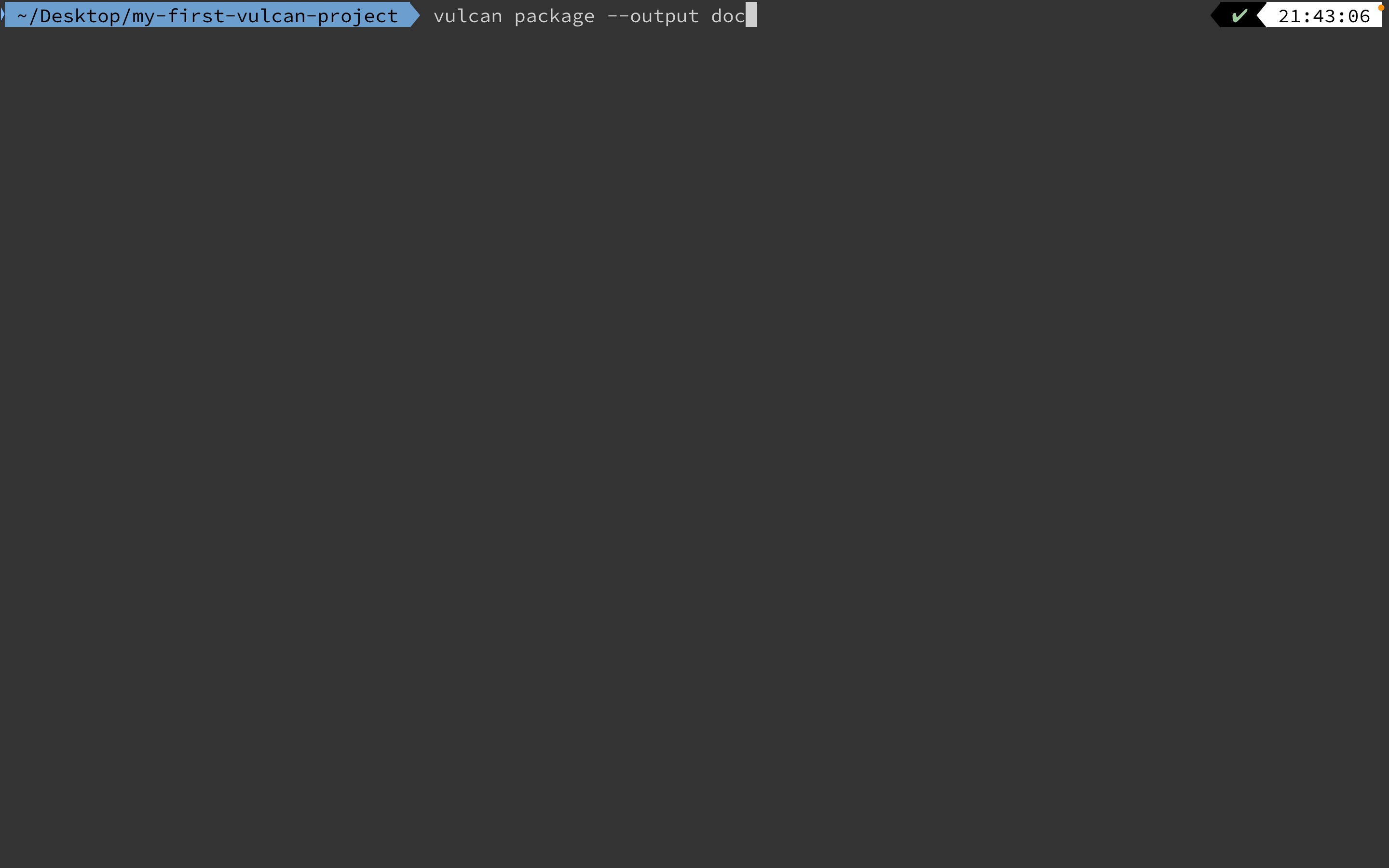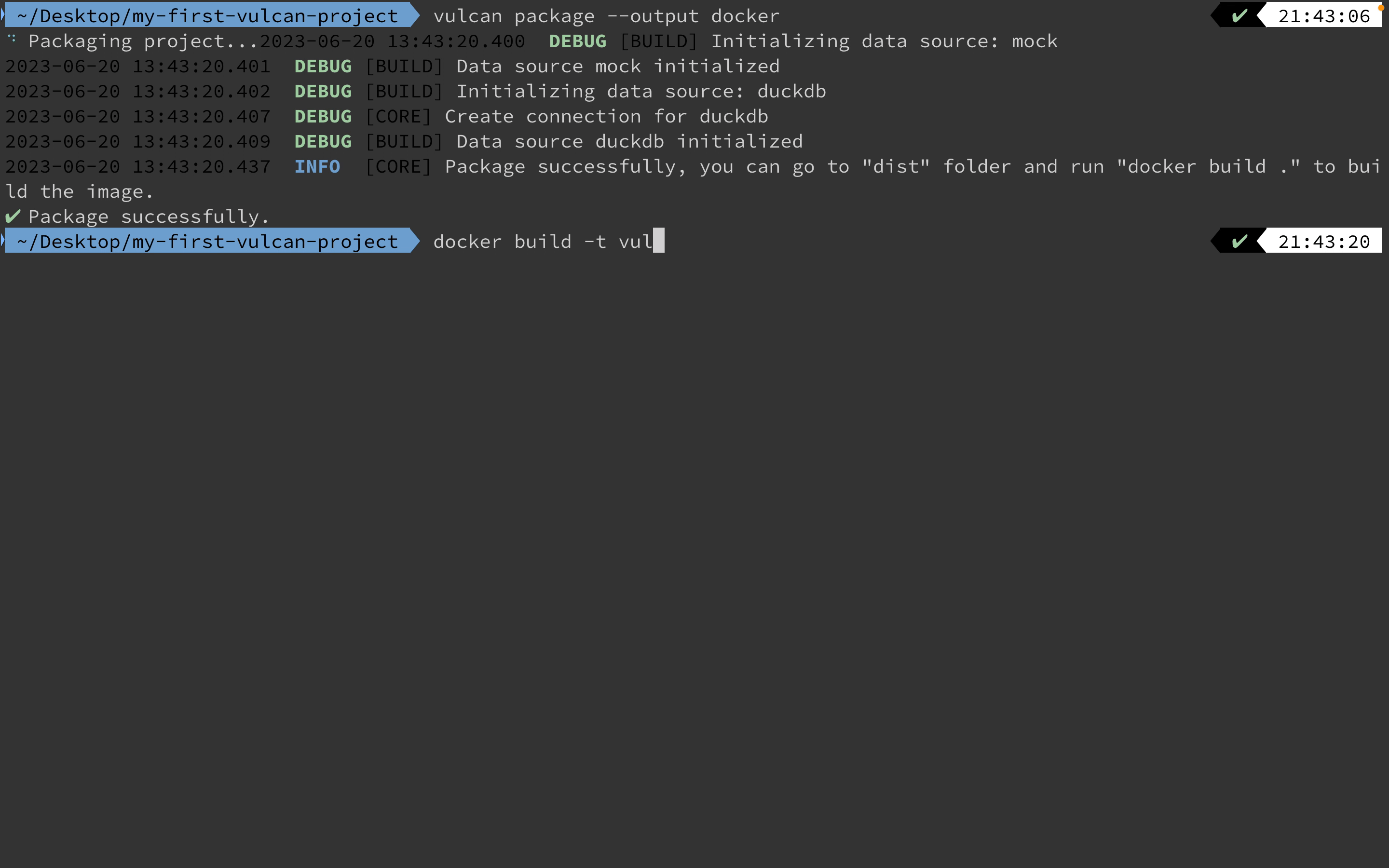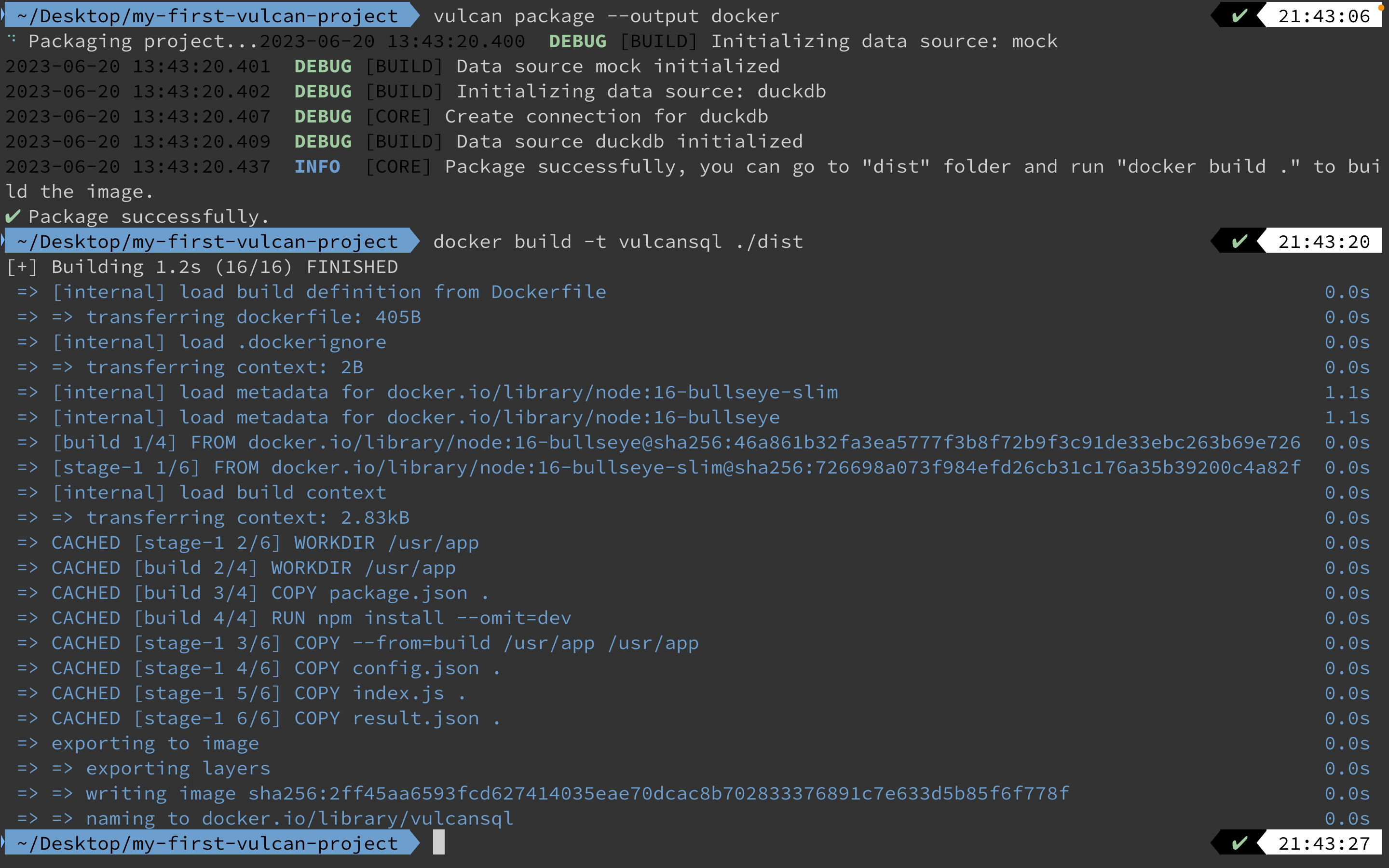
VulcanSQL offers flexible deployment options - whether you prefer Docker or command-based setups. Our 'package' command assists in bundling your assets, ensuring a smooth transition from development to deployment of your data APIs.
Share
VulcanSQL offers many data sharing options, seamlessly integrating your data into familiar applications within your workflow.
Automatically built API documentation based on OpenAPI.
Extract data from your API without needing SQL knowledge.
VulcanSQL enables seamless data sharing and integration within your known workflow.

Join the Community


What’s the problem you're trying to solve: ClickHouse blazing fast analytics database
I would like to support easy analytics API create with our great project
Describe the solution you’d like: https://clickhouse.com/docs/en/integrations/language-clients/nodejs

I have been trying to connect VulcanSQL with BigQuery but receive an error 'Not found'.
Also, not getting any endpoints in /localhost/doc
The credentials file is working fine as I tested the connection with DBeaver.
profiles, vulcan, sql and yaml files are at the below link.
Files: https://drive.google.com/drive/folders/1g1lyEG32x63hAzrIo2JK8vFAk5GpNC1U?usp=sharing

Support the VulcanSQL Catalog user interface for retrieving data in a more efficient and user-friendly manner.

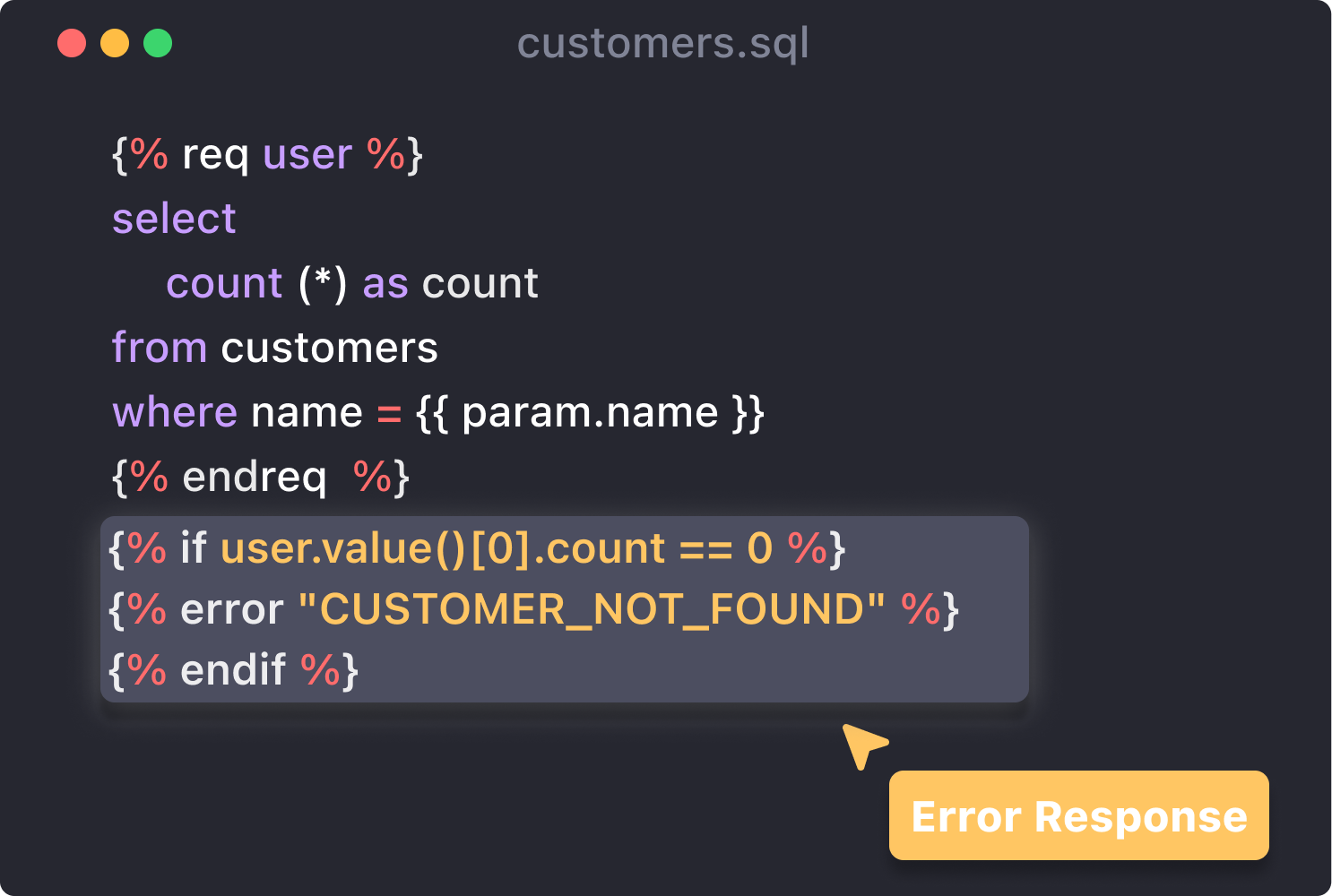
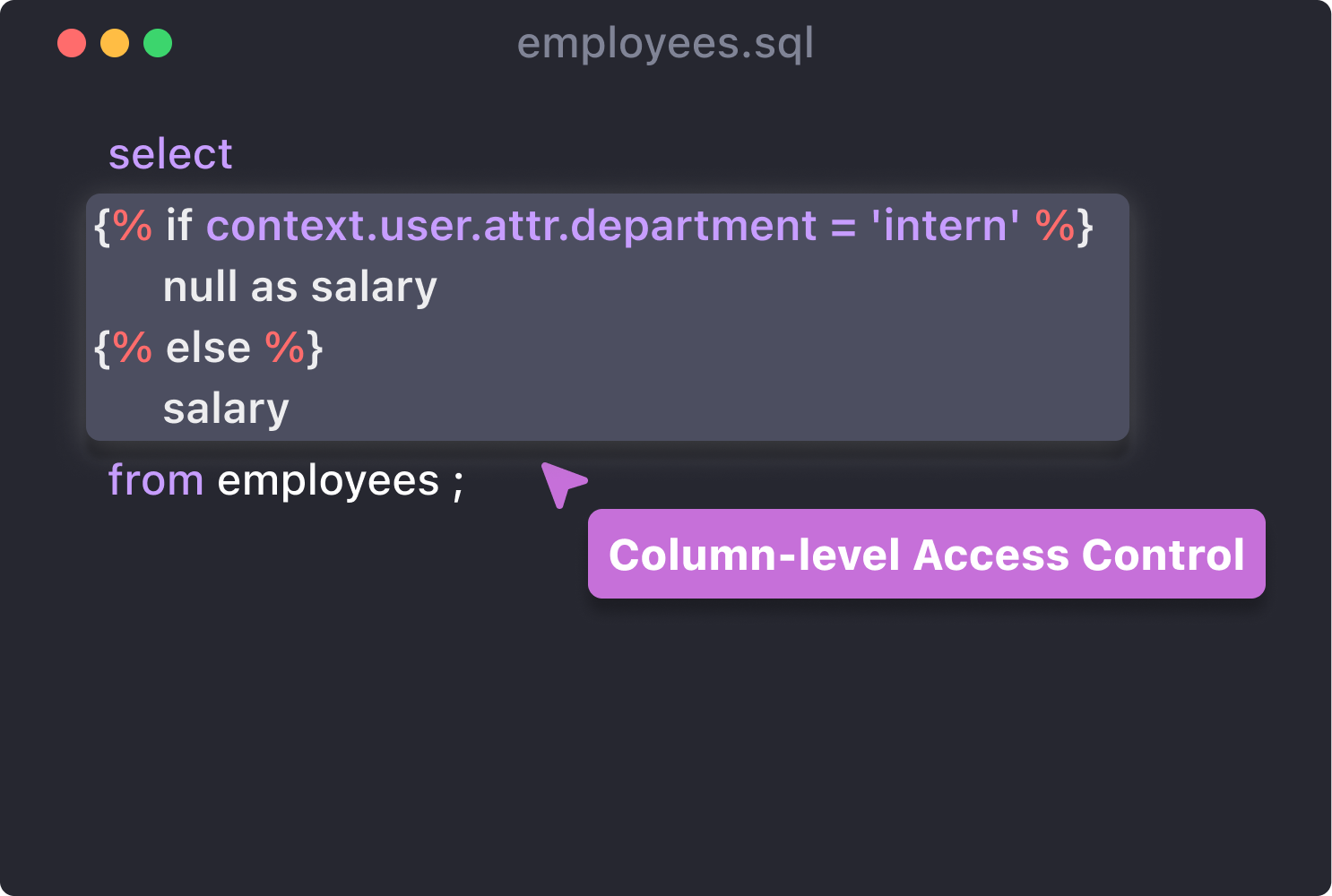
We can generate different queries depending on the user attribute, so it is easy to mask some columns manually
But manually masking each column might be annoying and unpredictable, we should provide "masking" tag with some masking functions.

This pull request implemented the snowflake export function to export the selected data to the local dir in parquet format.
export flow:
- Use the snowflake "COPY INTO..." command to convert the selected data into parquet format and stored in the user stage. This request will have a UUID generated by Snowflake, we will append this unique id to the stage file name to prevent concurrent copy requests with the same name which Snowflake will throw an error.
- Use the snowflake "GET ..." command to download the parquet file stored in the user stage to the local directory. We Use the "pattern" parameter in this command and filter out the file with the unique id.
- Use the snowflake "Remove ..." command to remove the parquet file in the user stage to avoid increasing costs. We Use the "pattern" parameter in this command and filter out the file with the unique id.

BigQuery is one of the most commonly used warehouses, we should add driver support.
Add BigQuery data source and update the document.